DRL笔记
条评论强化学习介绍
根据不同的分列方法可以将强化学习算法分成不同的种类:
1.基于概率(policy-based)和基于价值(value-based)
基于概率是强化学习中最直接的一种, 他能通过感官分析所处的环境, 直接输出下一步要采取的各种动作的概率, 然后根据概率采取行动, 所以每种动作都有可能被选中, 只是可能性不同. 而基于价值的方法输出则是所有动作的价值, 我们会根据最高价值来选着动作, 相比基于概率的方法, 基于价值的决策部分更为铁定, 毫不留情, 就选价值最高的, 而基于概率的, 即使某个动作的概率最高, 但是还是不一定会选到他.
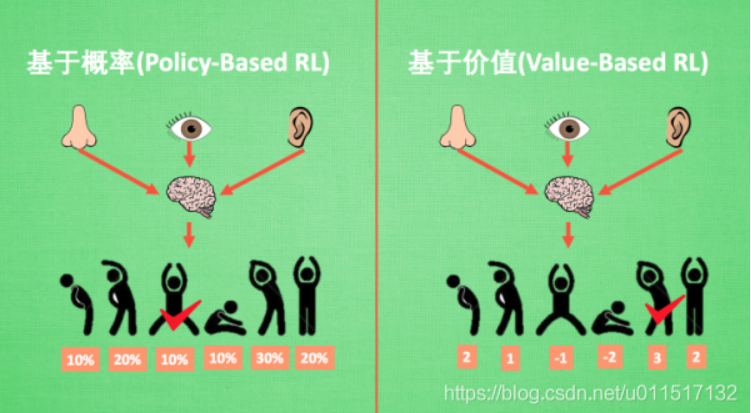
其中policy-based中的典型算法有Policy Gradients,value-based的典型算法有Q-learning、SARSA、DQN,两者重合的典型模型有AC、A2C、A3C
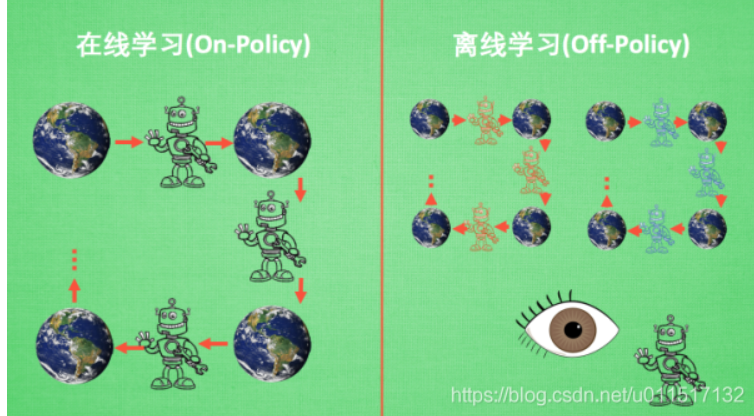
2.在线学习(on-policy)和离线学习(off-policy)
所谓在线学习(on-policy), 就是指我必须本人在场, 并且一定是本人边玩边学习, 学习者与环境必须产生实际的交互。
而离线学习(off-policy)是你可以选择自己玩, 也可以选择看着别人玩, 通过看别人玩来学习别人的行为准则。
on-policy的典型算法是SARSA, off-policy的典型算法是Q-learning、DQN。
on-policy是的学习者必学进行完一系列实际动作后才能产生样本,这样效率往往较慢。off-policy可以从以往的经验或别人的动作开学习,效率往往比较高。
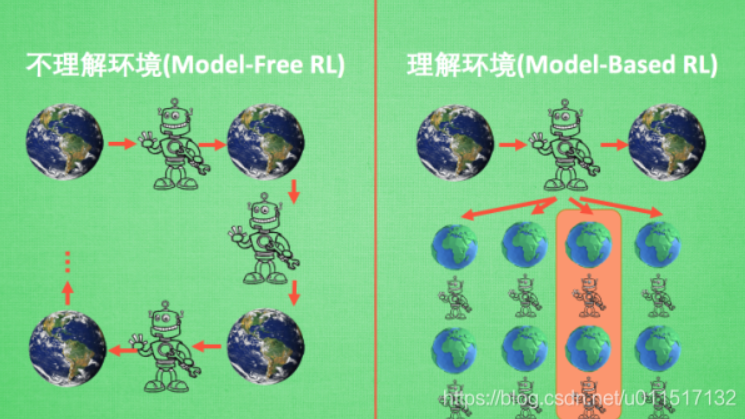
3.model-based和model-free
可以将所有强化学习的方法分为理不理解所处环境,如果我们不尝试去理解环境, 环境给了我们什么就是什么. 我们就把这种方法叫做 model-free, 这里的 model 就是用模型来表示环境, 那理解了环境也就是学会了用一个模型来代表环境, 所以这种就是 model-based 方法.
SARSA算法原理
强化学习的主要功能就是让agent学习尽可能好的动作action,使其后续获得的奖励尽可能的大。
假设在时刻t时,处于状态长期奖励为: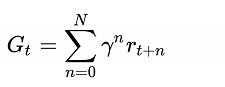





二、SARSA代码
此处直接参考莫烦python的强化学习教程进行代码编写,在基础上说明每一行代码的用途
1.environment的编写
首先RL需要一个环境,因为我们控制不了环境(比如下围棋时我们不不能改变棋盘的大小,何落子方式,只能只能在范围内落在线与线之间的交叉点上),这个环境是不可以改变的,因此后面的Q-learning也将沿用此环境。通常不同的问题有不同环境,我们真正需要关注的是agent即算法逻辑的编写。
此处以走方格为例编写一个environment
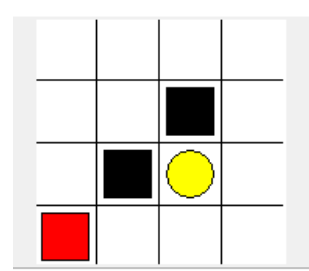
maze_env
1 | """ |
agent
1 | from maze_env import Maze #即为上面的environment |
Q-learning、



用同一个env
qlearnning-agent
1 | from maze_env import Maze |
唯一不同是on ->off
并未真正执行a’,而是选择所有a中Q值最大的一项;
DQN



DQN的算法

学习策略:observation
更新方式一:更新慢,需要将所有的动作执行完才能更新

 更新方式二:
更新方式二:
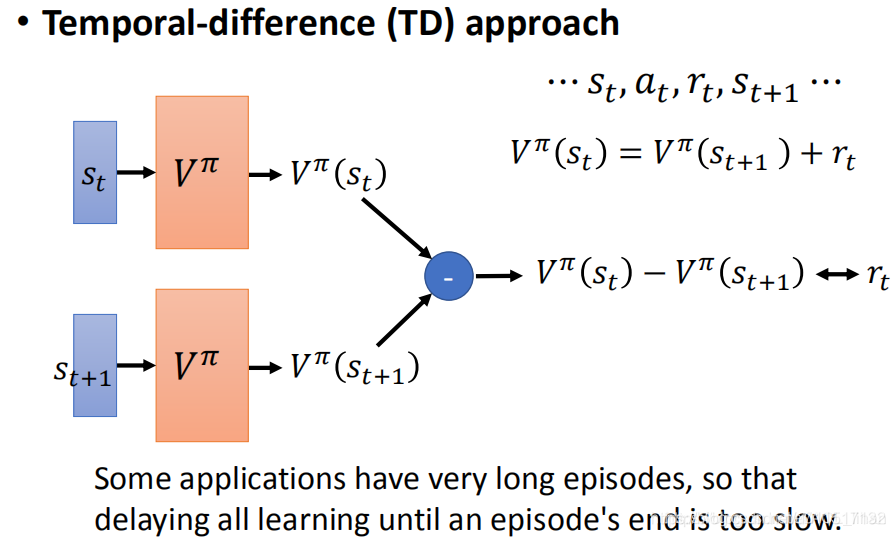




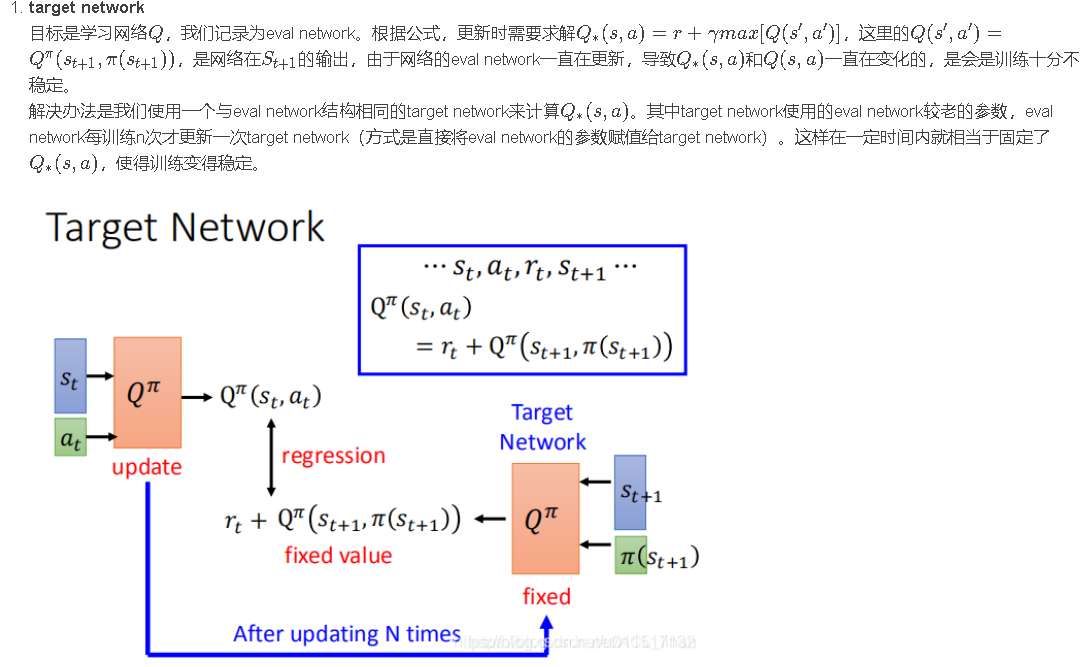
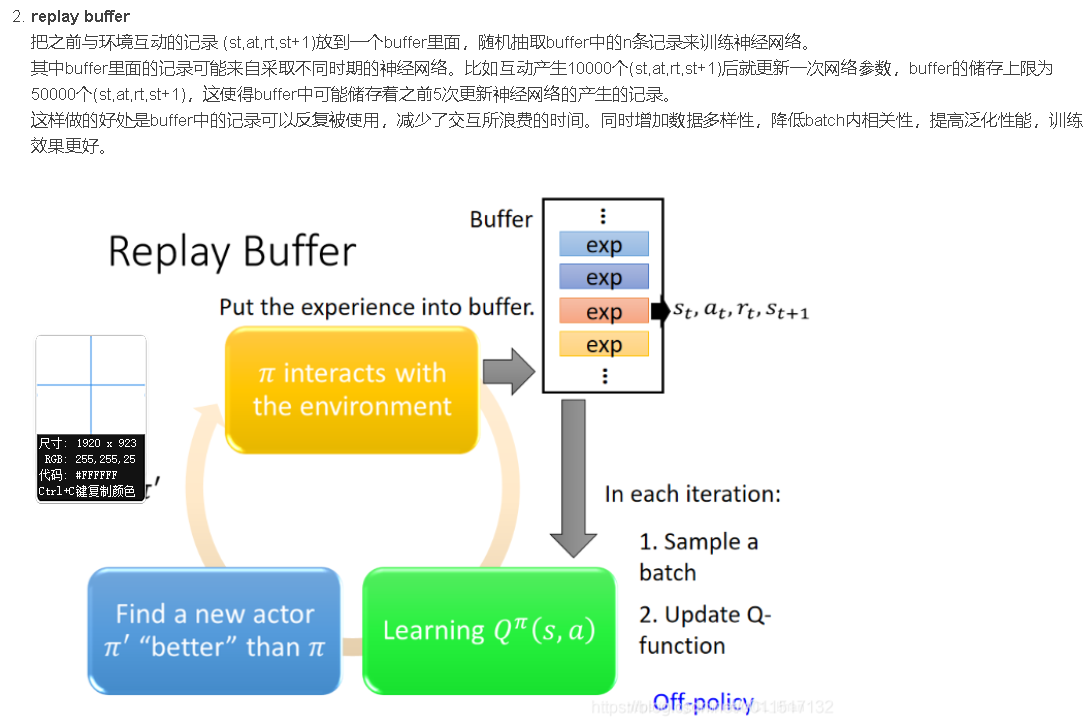
但上面算法中,也有一些与Q-learning不同的地方,这是使DQN变得更加有效和技巧:
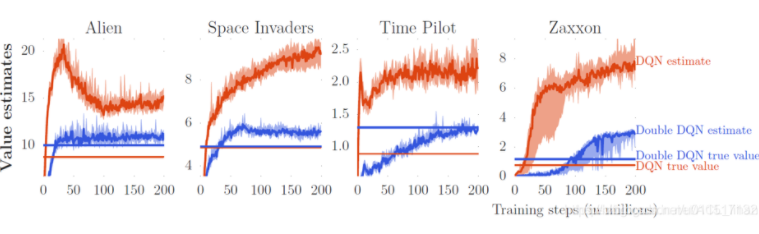
Dobule DQN


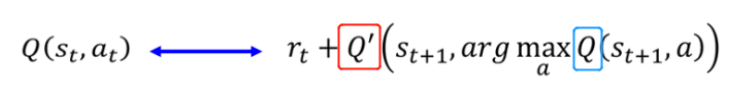


1 | class Double_DeepQNetwork(object): |
Double-DQN的agent编写与DQN几乎一样只是在求q估计的时候先用eval network求出价值最大的动作,再讲这个动作带入target network。
之前在DQN中使用的公式为
1 | q_target[batch_index, eval_act_index]=reward+self.gamma * np.max(q_next, axis=1) |
Duling DQN
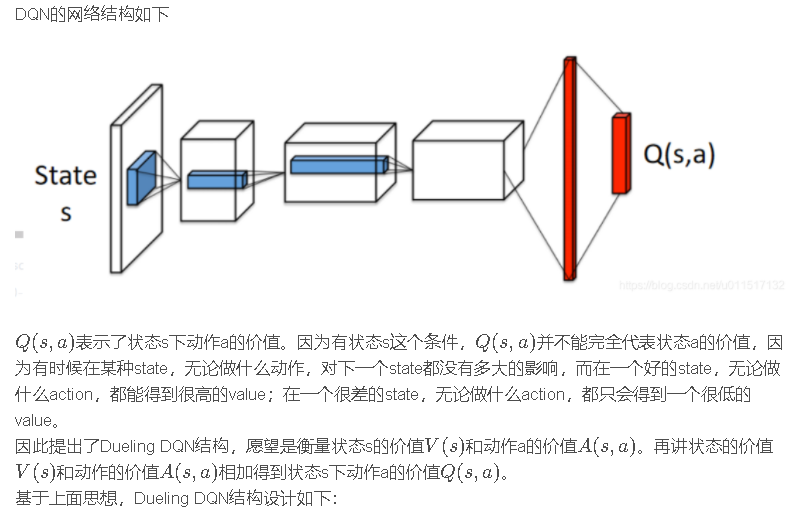
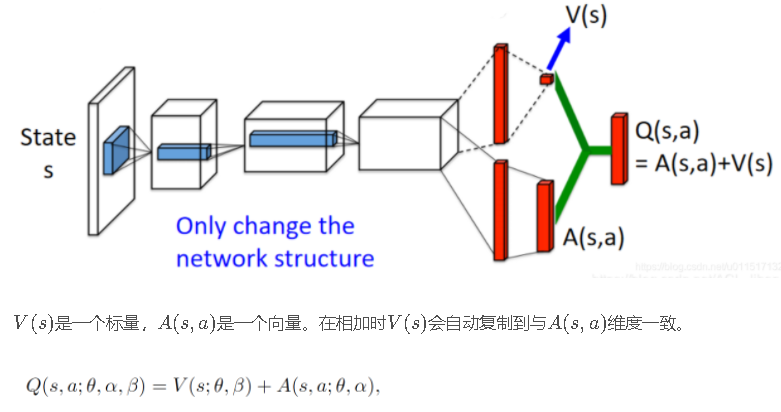

Dueling DQN与DQN的网络结构不同,其他过程相似。着重是更改原来DQN Agent的build_net()方法。
之前构建的方式是通过一个隐藏层直接获得q值
1 | with tf.variable_scope('l1'): |
完整的dueling DQN的Agent的代码如下:
1 | class Dueling_DeepQNetwork(object): |
Policy Gradient
之前说的SARSA、Q-learning、DQN学习的都是在状态s下动作a的价值,属于value-based的方法。而Policy Gradient学习的是在状态s下每个动作a被选择的概率,属于policy-based的方法。
我们先说Policy Gradient的整体思想,之后将整体思想进行拆分,产生Policy Gradient每一步的流程。
Policy Gradient的网络要学习的是状态下动作输出的概率。按照常识来讲,可以获得越大的奖励的动作应该被选择的概率是越大的。需要注意的是这里所说的奖励并不是一个动作单步的奖励,而是当整个游戏结束时,这个动作整体所产生的价值,这个价值我们叫做advantage。因此我们的网络要学习的目标就是:按照每个动作的概率进行选择时,获得的奖励的期望值是最大的。
https://www.jianshu.com/p/428b640046aa
策略梯度
在PG算法中,我们的Agent又被称为Actor,Actor对于一个特定的任务,都有自己的一个策略π,策略π通常用一个神经网络表示,其参数为θ。从一个特定的状态state出发,一直到任务的结束,被称为一个完整的eposide,在每一步,我们都能获得一个奖励r,一个完整的任务所获得的最终奖励被称为R。这样,一个有T个时刻的eposide,Actor不断与环境交互,形成如下的序列τ:

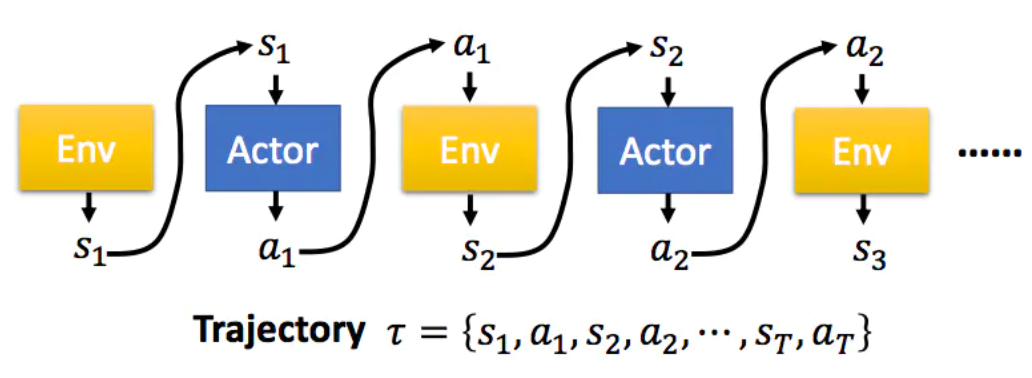
这样一个序列τ是不确定的,因为Actor在不同state下所采取的action可能是不同的,一个序列τ发生的概率为:
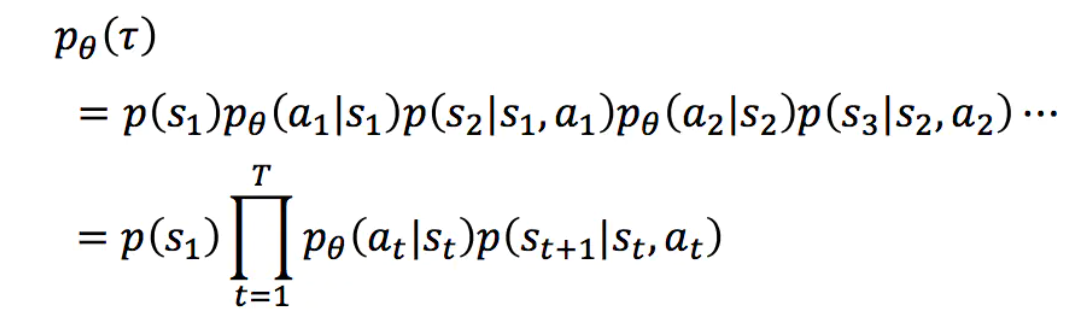
序列τ所获得的奖励为每个阶段所得到的奖励的和,称为R(τ)。因此,在Actor的策略为π的情况下,所能获得的期望奖励为:
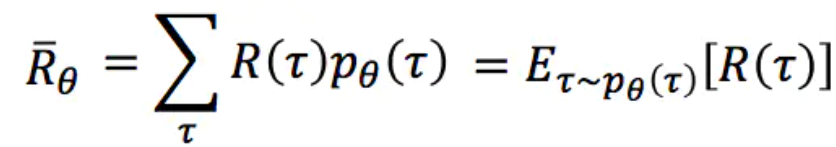
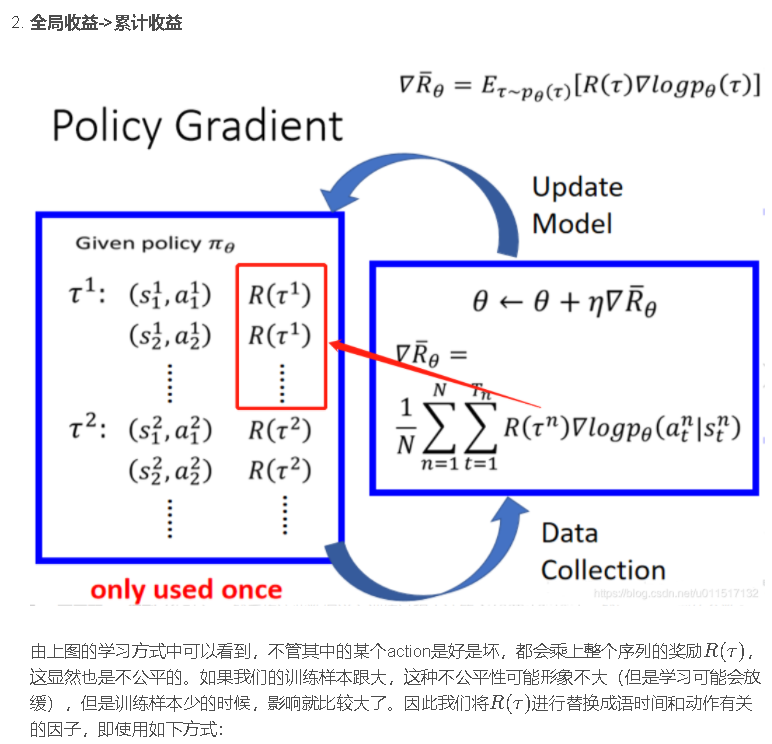
而我们的期望是调整Actor的策略π,使得期望奖励最大化,于是我们有了策略梯度的方法,既然我们的期望函数已经有了,我们只要使用梯度提升的方法更新我们的网络参数θ(即更新策略π)就好了,所以问题的重点变为了求参数的梯度。梯度的求解过程如下:

首先利用log函数求导的特点进行转化,随后用N次采样的平均值来近似期望,最后,我们将pθ展开,将与θ无关的项去掉,即得到了最终的结果。
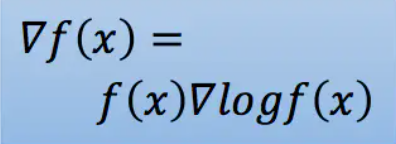

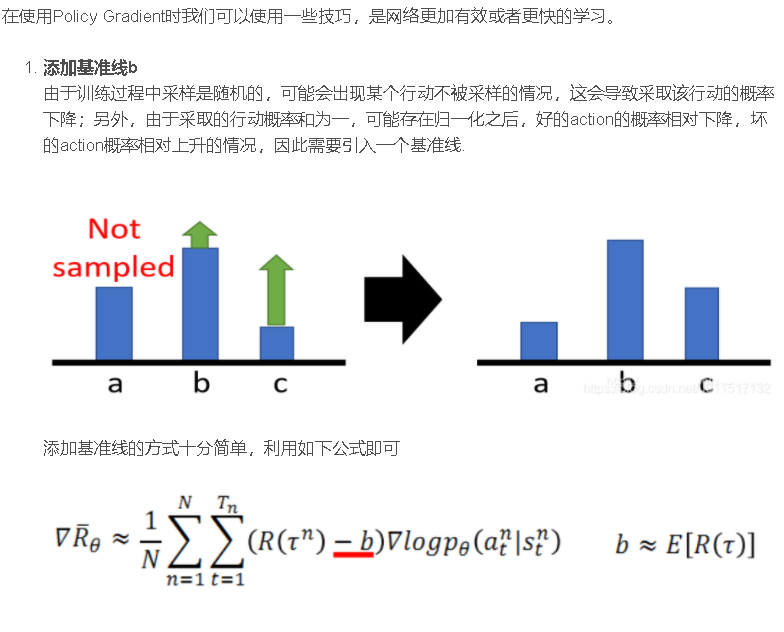
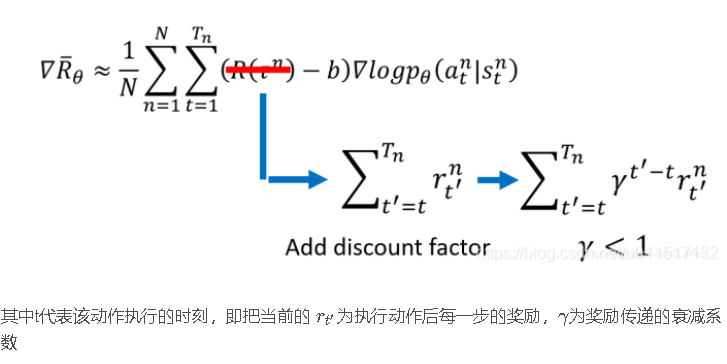

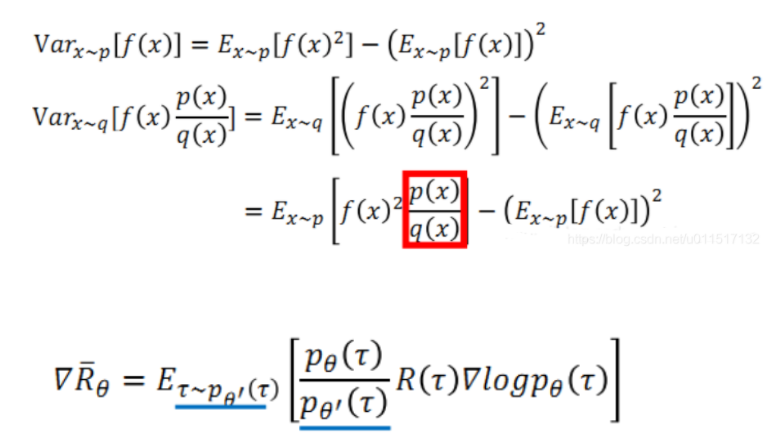
policy gradient 的Agent的实现
1 | from maze_env_drl import Maze |
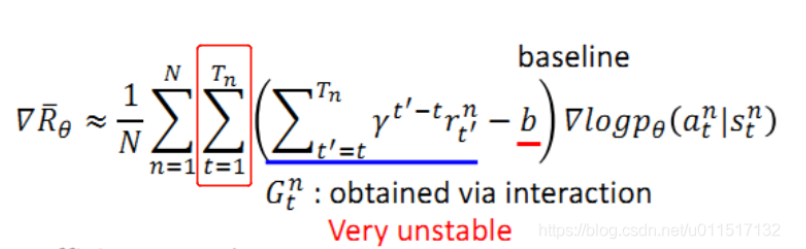
可以看出policy gradient是基于回合更新的,因此我们需要需要很大的耐心和环境产生交互样本,进行回合训练,并且由于每个回合是不稳定的,因此我们需要的大量的样本
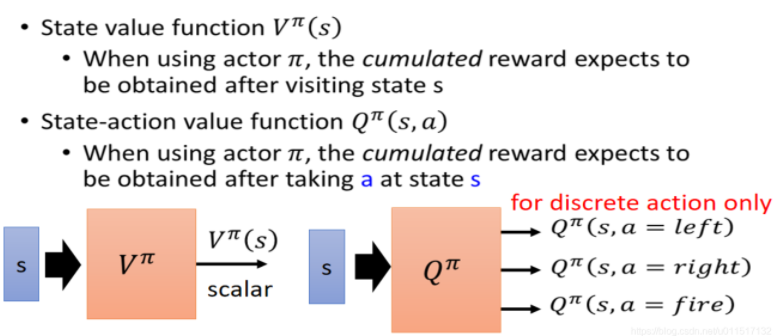
Q-learning学习的是每个动作的价值,要求动作必须是离散的。
policy gradient和Q-learning都有各自的优缺点。我们可以将两者整合起来,即记忆使用off-policy的学习,也可以使用连续的动作。
下面两段话摘自莫烦python的强化学习教程:Actor-Critic 的 Actor 的前生是 Policy Gradients, 这能让它毫不费力地在连续动作中选取合适的动作, 而 Q-learning 做这件事会瘫痪. 那为什么不直接用 Policy Gradients 呢? 原来 Actor Critic 中的 Critic 的前生是 Q-learning 或者其他的 以值为基础的学习法 , 能进行单步更新, 而传统的 Policy Gradients 则是回合更新, 这降低了学习效率。
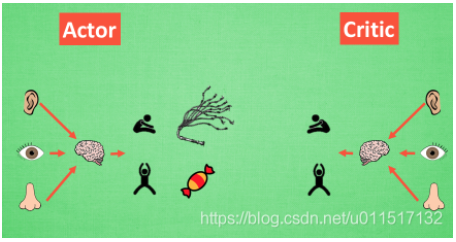
Actor 和 Critic, 他们都能用不同的神经网络来代替 . 在 Policy Gradients 的影片中提到过, 现实中的奖惩会左右 Actor 的更新情况. Policy Gradients 也是靠着这个来获取适宜的更新. 那么何时会有奖惩这种信息能不能被学习呢? 这看起来不就是 以值为基础的强化学习方法做过的事吗. 那我们就拿一个 Critic 去学习这些奖惩机制, 学习完了以后. 由 Actor 来指手画脚, 由 Critic 来告诉 Actor 你的那些指手画脚哪些指得好, 哪些指得差, Critic 通过学习环境和奖励之间的关系, 能看到现在所处状态的潜在奖励, 所以用它来指点 Actor 便能使 Actor 每一步都在更新, 如果使用单纯的 Policy Gradients, Actor 只能等到回合结束才能开始更新。
以前我们用过回合的奖励来进行policy gradient的更新,Actor-Critic将回合奖励替换成动作的价值,来对网络进行学习,自然就将Q-learning结合了起来:
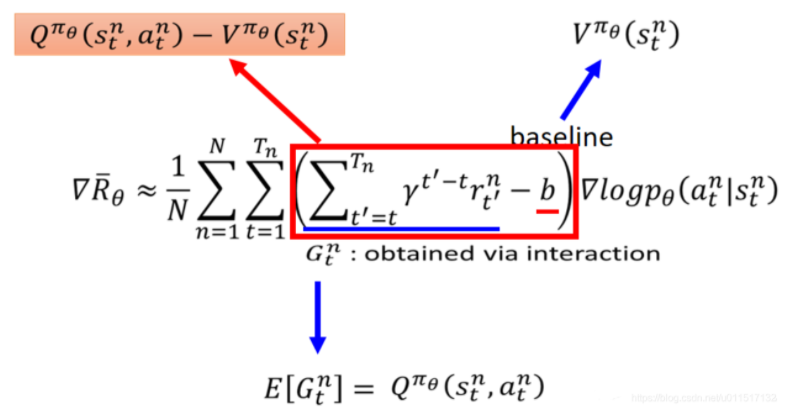
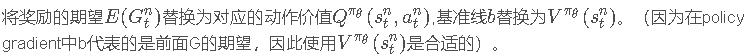
在PG策略中,如果我们用Q函数来代替R,同时我们创建一个Critic网络来计算Q函数值,那么我们就得到了Actor-Critic方法。Actor参数的梯度变为:
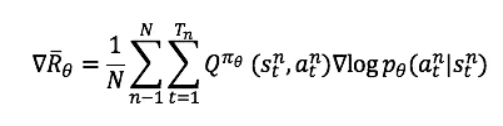
此时的Critic根据估计的Q值和实际Q值的平方误差进行更新,对Critic来说,其loss为:
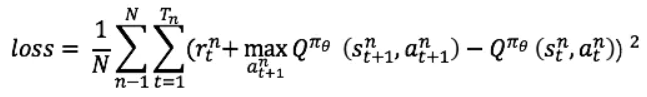
AC代码的实现地址为:https://github.com/princewen/tensorflow_practice/tree/master/RL/Basic-AC-Demo
Advantage Actor-Critic(A2C)

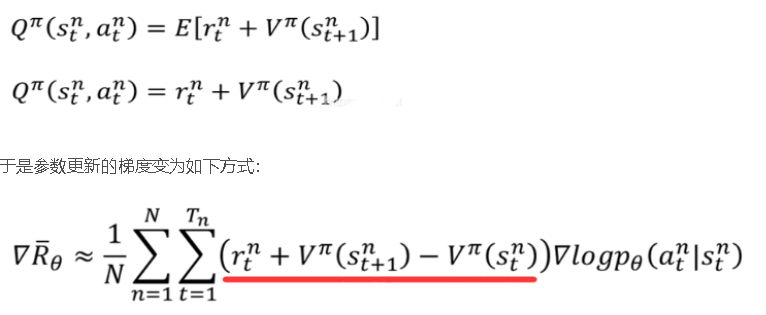
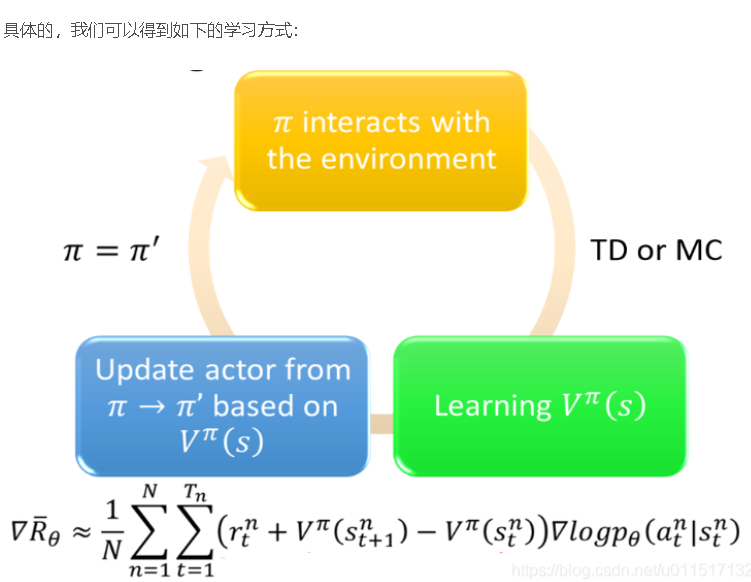


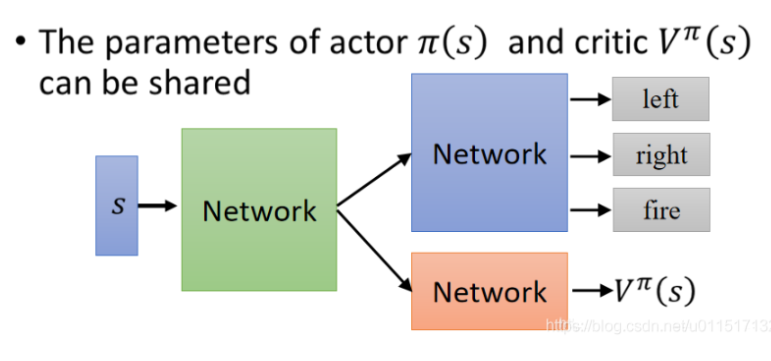
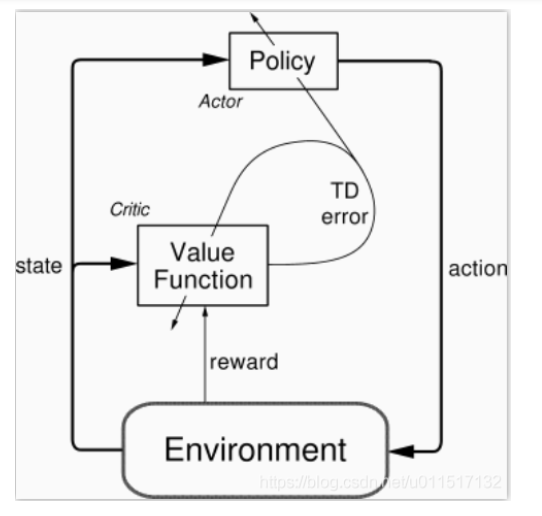
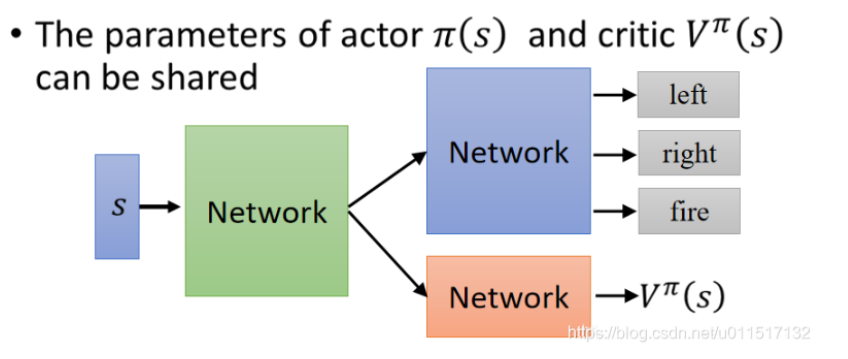
本文基于如下架构进行Advantage Actor-Critic的Agent实现。其中Actor和Critic的第一层权重共享:
Q-learning
Q-learning是一种value_based的方法。
