入门深度学习
条评论感知器
感知机是二分类的线性分类模型,其输入为实例的特征向量,输出为实例的类别(分别取+1和-1),属于判别模型。
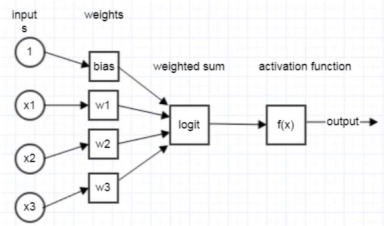
图1 模型
如图1所示,假设输入空间(特征向量)是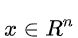
,输出空间为f(x)∈{-1,+1},输入x∈X表示实例的特征向量,对应于输入空间的点,输出表示实例的类别,则由输入空间到输出空间的表达形式为:
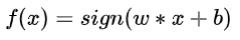
其中w,b称为模型的参数,
称为权值,b称为偏置,w*x表示为w,x的内积,其中
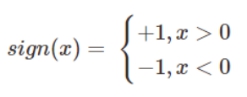
如果我们将sign(x)称之为激活函数,sign(x)将大于0的分为1,小于0的分为-1。
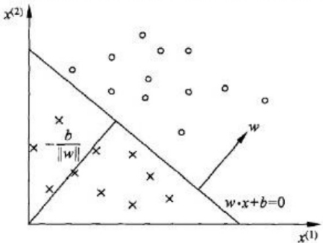
图2 直线分隔超平面
如图2所示,其中w为法向量,b为截距,此直线用于分离超平面。
问题在于确定w和b,也就是在学习参数w与b,确定了w与b,图上的直线(高维空间下为超平面)也就确定了,那么以后来一个数据点,我用训练好的模型进行预测判断,如果大于0就分类到+1,如果小于0就分类到-1。
解决这个问题首先要找到损失函数,然后转化为最优化问题,用梯度下降等方法进行更新,最终得到我们模型的参数w,b。
线性单元和梯度下降
感知器有一个问题,当面对的数据集不是线性可分的时候,『感知器规则』可能无法收敛,这意味着我们永远也无法完成一个感知器的训练。
为了解决这个问题,我们使用一个可导的线性函数来替代感知器的阶跃函数,这种感知器就叫做线性单元。线性单元在面对线性不可分的数据集时,会收敛到一个最佳的近似上。
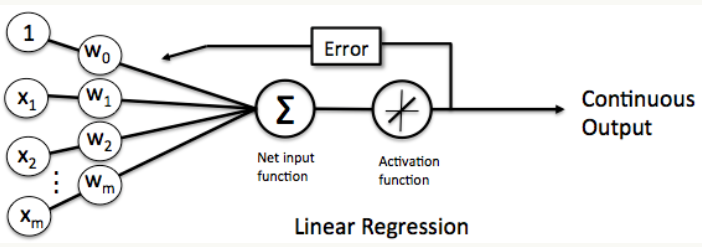
设置线性单元的激活函数为 f(x) = x,这样替换了激活函数之后,线性单元将返回一个实数值而不是0,1分类。因此线性单元用来解决回归问题而不是分类问题。
我们可以用这样的一个特征向量来表示他 x= (5, IT, 百度, T6)。
既然输入变成了一个具备四个特征的向量,相对应的,仅仅一个参数就不够用了,我们应该使用4个参数w1.w2.w3.w4,每个特征对应一个。这样,我们的模型就变成
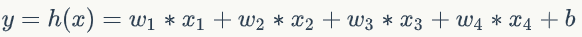
我们还可以把上式写成向量的形式
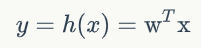
长成这种样子模型就叫做线性模型
监督学习和无监督学习
监督学习,它是说为了训练一个模型,我们要提供这样一堆训练样本:每个训练样本既包括输入特征,也包括对应的输出(输出也叫做标记,label),用这样的样本去训练模型,让模型既看到我们提出的每个问题(输入特征),也看到对应问题的答案(标记)。当模型看到足够多的样本之后,它就能总结出其中的一些规律。然后,就可以预测那些它没看过的输入所对应的答案了。
无监督学习,这种方法的训练样本中只有x而没有y。模型可以总结出特征的一些规律,但是无法知道其对应的答案。
现在,让我们只考虑监督学习
我们当然希望模型计算出来的和真实值越接近越好。
我们可以用差的平方的1/2来表示它们的接近程度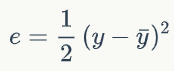
我们把这个叫做单个样本的误差。至于为什么前面要乘1/2,是为了后面计算方便。
训练数据中会有很多样本,比如N个,我们可以用训练数据中所有样本的误差的和,来表示模型的误差,也就是
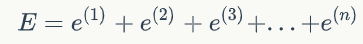
我们还可以把上面的式子写成和式的形式。使用和式,不光书写起来简单,逼格也跟着暴涨,一举两得。所以一定要写成下面这样
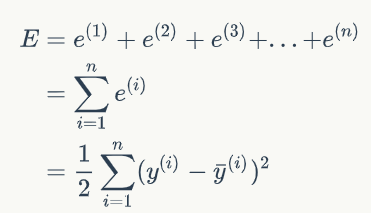

其中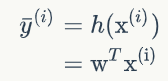

梯度下降优化算法
卷积神经网络
近几年卷积神经网络中,激活函数往往不选择sigmoid或tanh函数,而是选择relu函数。
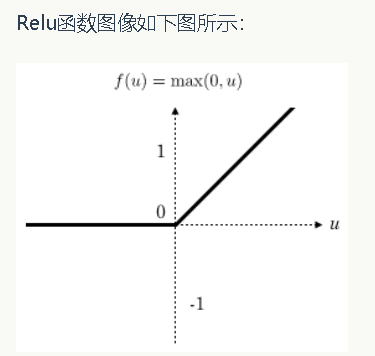
优势:
速度快 和sigmoid函数需要计算指数和倒数相比,relu函数其实就是一个max(0,x),计算代价小很多。
减轻梯度消失问题 在使用反向传播算法进行梯度计算时,每经过一层sigmoid神经元,梯度就要乘上一个sigmoid导数,导致梯度越来越小,而relu函数的导数是1,不会导致梯度变小。
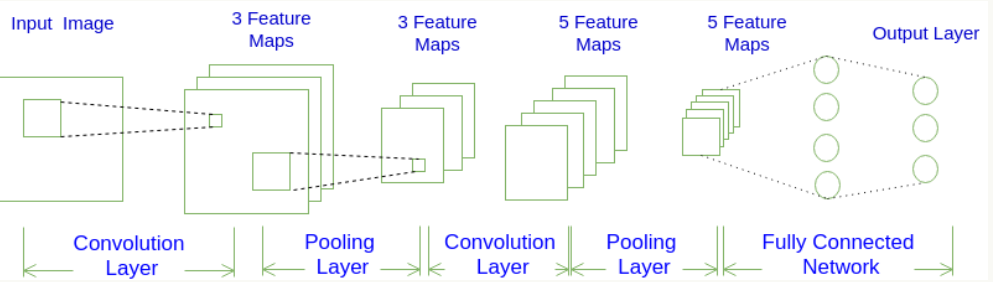
常用架构模式为:INPUT -> [[CONV]*N -> POOL?]*M -> [FC]*K
也就是N个卷积层叠加,然后(可选)叠加一个Pooling层,重复这个结构M次,最后叠加K个全连接层。
卷积层输出值的计算
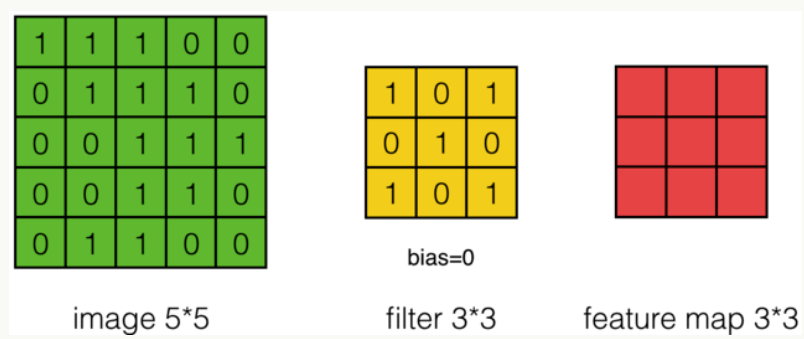
我们用一个简单的例子来讲述如何计算卷积,然后,我们抽象出卷积层的一些重要概念和计算方法。
假设有一个5 * 5的图像,使用一个3 * 3的filter进行卷积,想得到一个3 * 3的Feature Map,如下所示:
Pooling层输出值的计算
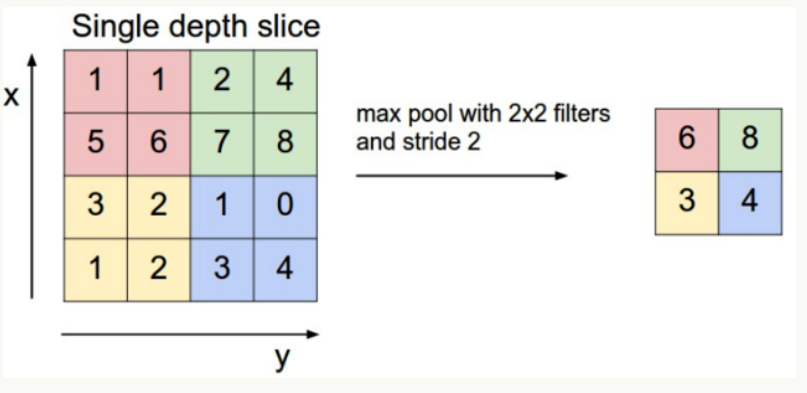
Pooling层主要的作用是下采样,通过去掉Feature Map中不重要的样本,进一步减少参数数量。Pooling的方法很多,最常用的是Max Pooling。Max Pooling实际上就是在nn的样本中取最大值,作为采样后的样本值。下图是22 max pooling:
除了Max Pooing之外,常用的还有Mean Pooling——取各样本的平均值。
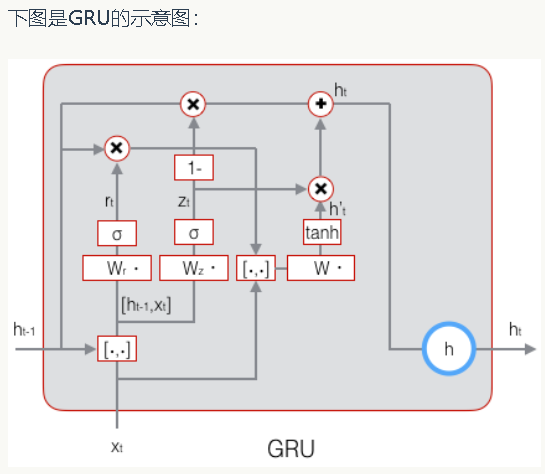
循环神经网络
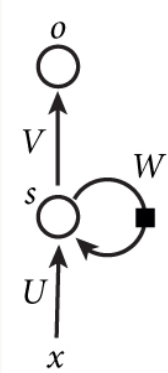
如果把上面有W的那个带箭头的圈去掉,它就变成了最普通的全连接神经网络。x是一个向量,它表示输入层的值(这里面没有画出来表示神经元节点的圆圈);s是一个向量,它表示隐藏层的值(这里隐藏层面画了一个节点,你也可以想象这一层其实是多个节点,节点数与向量s的维度相同);U是输入层到隐藏层的权重矩阵,o也是一个向量,它表示输出层的值;V是隐藏层到输出层的权重矩阵。那么,现在我们来看看W是什么。循环神经网络的隐藏层的值s不仅仅取决于当前这次的输入x,还取决于上一次隐藏层的值s。权重矩阵 W就是隐藏层上一次的值作为这一次的输入的权重。
如果我们把上面的图展开,循环神经网络也可以画成下面这个样子:
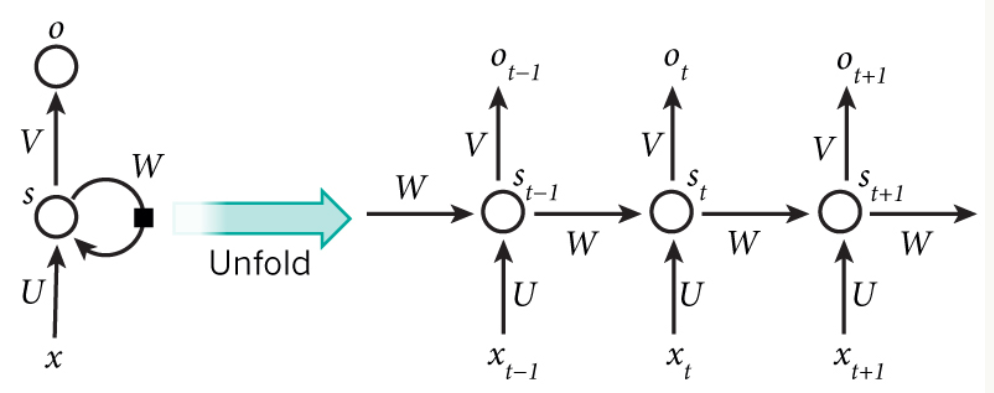

式1是输出层的计算公式,输出层是一个全连接层,也就是它的每个节点都和隐藏层的每个节点相连。V是输出层的权重矩阵,g是激活函数。式2是隐藏层的计算公式,它是循环层。U是输入x的权重矩阵,W是上一次的值作为这一次的输入的权重矩阵,f是激活函数。
从上面的公式我们可以看出,循环层和全连接层的区别就是循环层多了一个权重矩阵 W。

理解 向量求导
术语 降维
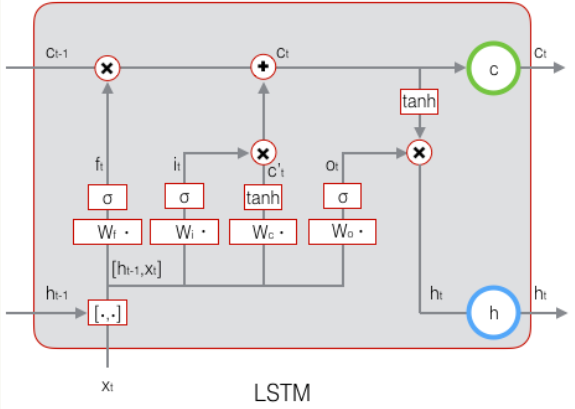
长短时记忆网络(LSTM)
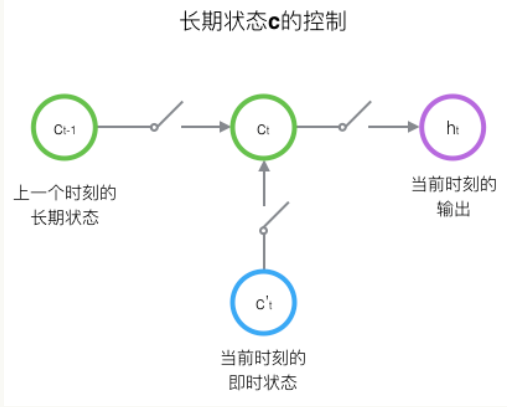
原始RNN的隐藏层只有一个状态,即h,它对于短期的输入非常敏感。那么,假如我们再增加一个状态,即c,让它来保存长期的状态,那么问题不就解决了么?如下图所示:
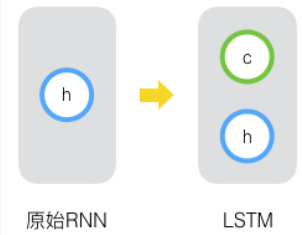
新增加的状态c,称为**单元状态(cell state)**。我们把上图按照时间维度展开:
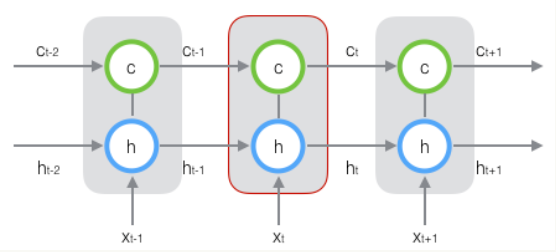

LSTM的关键,就是怎样控制长期状态c。在这里,LSTM的思路是使用三个控制开关。第一个开关,负责控制继续保存长期状态c;第二个开关,负责控制把即时状态输入到长期状态c;第三个开关,负责控制是否把长期状态c作为当前的LSTM的输出。三个开关的作用如下图所示: