李雅普诺夫论文
条评论基于李亚普诺夫指导的深度强化学习在移动边缘计算网络中的稳定在线计算卸载
背景、动机
本文考虑一个多用户MEC网络,该网络具有时变无线信道和在连续时间帧内随机的用户任务数据到达,满足长期数据队列稳定性和平均功率约束的情况下,最大化网络数据处理能力。
我们将该问题公式化为一个多阶段随机混合整数非线性规划(MINLP)问题,
LyDROO首先应用李雅普诺夫优化将多阶段随机MINLP解耦为确定性每帧MINLP子问题。
计算任务数据在连续的时间帧中随机到达WDs的数据队列。我们的目标是设计一个在线计算卸载算法,在这个意义上,每个时间帧的决策是在不知道随机的未来实现的假设下做出的信道条件和数据到达。目标是根据长期数据队列稳定性和平均功率约束,最大化网络数据处理能力。
1在线稳定计算卸载设计:考虑随机衰落信道和数据到达,我们将问题公式化为多阶段随机MINLP问题,以最大化所有WDs的长期平均加权和计算速率(即每秒处理的比特数),服从队列稳定性和平均功率约束。特别地,我们将在每个时间帧中做出最优卸载和资源分配决策,而不需要假设知道随机信道条件和数据到达的未来实现。
2集成李雅普诺夫-DRL框架:为了解决这个问题,我们提出了一个新的李雅普诺夫框架,它结合了李雅普诺夫优化和DRL的优点。特别地,我们首先应用李雅普诺夫优化将多阶段随机MINLP解耦为每帧确定性MINLP问题。然后在每一帧中,我们集成了基于模型的优化和无模型DRL,以非常低的计算复杂度来解决每帧的MINLP问题。特别地,我们表明所提出的LyDROO框架不仅保证了长期队列稳定性和平均功率约束,而且以在线方式获得了最优的计算速率性能。
3集成优化和学习:LyDROO采用演员-评论家结构来解决每帧MINLP问题。actor模块是一个DNN模块,它根据包括信道增益和对所有WDs的积压进行排队。批评模块通过解析地解决最优资源分配问题来评估二进制卸载动作。与在评论模块中使用无模型DNN的传统演员-评论结构相比,所提出的方法利用模型信息来获得对动作的准确评估,从而享有DRL训练过程的更健壮和更快的收敛。
4平衡探索和开发:LyDROO部署了一种有噪声的保序量化方法来生成卸载动作,该方法在DRL算法设计中优雅地平衡了探索和开发的权衡(即面向性能或多样性),以确保快速训练收敛。此外,该量化方法可以在训练过程中自适应地调整其参数,从而在不影响收敛性能的情况下显著降低计算复杂度。
摘要
计算卸载是动态边缘环境下提高移动边缘计算(MEC)网络计算性能的有效方法。本文考虑一个多用户MEC网络,该网络具有时变无线信道和在连续时间帧内随机的用户任务数据到达。具体来说,我们旨在设计一种在线计算卸载算法,在满足长期数据队列稳定性和平均功率约束的情况下,最大化网络数据处理能力。在线算法是实用的,因为每个时间帧的决策是在不假设知道随机信道条件和数据到达的未来实现的情况下做出的。我们将该问题公式化为一个多阶段随机混合整数非线性规划(MINLP)问题,该问题联合确定二进制卸载(每个用户在本地或在边缘服务器上计算任务)和顺序时间帧中的系统资源分配决策。为了解决不同时间框架决策中的耦合问题,我们提出了一个新的框架,名为LyDROO,它结合了李雅普诺夫优化和深度强化学习(DRL)的优点。具体来说,LyDROO首先应用李雅普诺夫优化将多阶段随机MINLP解耦为确定性每帧MINLP子问题。通过这样做,它保证通过解决每帧小得多的子问题来满足所有长期约束。然后,LyDROO集成了基于模型的优化和无模型DRL,以极低的计算复杂度解决了每帧MINLP问题。仿真结果表明,在不同的网络设置下,该算法在稳定系统所有队列的同时,获得了最优的计算性能。此外,它导致非常低的计算时间,特别适合在快衰落环境中实时实现。
动机
新兴的移动边缘计算(MEC)技术被广泛认为是增强无线设备(WDs)计算性能的关键解决方案[2],尤其是对于尺寸受限、设备上电池和计算能力较低的IoT(物联网)设备。随着MEC服务器部署在无线接入网络的边缘,例如蜂窝基站,WDs可以将密集的计算任务卸载到附近的边缘服务器,以减少计算能量和时间成本。与卸载所有任务用于边缘执行的天真方案相比,机会计算卸载(动态分配要在本地或在ES系统上计算的任务)在时变网络条件下表现出显著的性能改进,例如无线信道增益[3]、收获的能量水平[4]、任务输入输出相关性[5]和边缘缓存可用性[6]等。
已经对机会计算卸载进行了广泛的研究,以优化多用户MEC网络的计算性能[5]–[9]。通常,它涉及求解混合整数非线性规划(MINLP),该规划共同确定二进制卸载(即,卸载计算与否)和通信/计算资源分配(例如,任务卸载时间和本地/边缘中央处理器频率)决策。解决这些问题通常需要极高的计算复杂度,尤其是在大规模网络中。因此,许多工作集中于设计复杂度降低的次优算法,例如基于局部搜索的启发式[5],[8],面向分解的搜索[8],以及二元变量的凸松弛[9],[25]等。然而,除了性能损失之外,上述次优算法仍然需要大量的数值迭代来产生令人满意的解。实际上,一旦系统参数(如无线链路质量)发生变化,就需要频繁地重新解决MINLP问题。因此,在高度动态的MEC环境中实现传统的优化算法成本太高。
数据驱动的深度强化学习(DRL)的最新发展为解决在线计算卸载问题提供了一个有前途的替代方案。简而言之,DRL框架采用无模型方法,使用深度神经网络(DNNs)直接学习从“状态”(例如,时变系统参数)到“动作”(例如,卸载决策和资源分配)的最佳映射,以通过与环境的重复交互来最大化“回报”(例如,数据处理速率)[10]。它消除了MINLP的复杂计算,并在运行中自动学习过去的经验,而不需要手动标记训练数据样本,因此对于在线实现特别有利。许多研究已经应用DRL技术设计了MEC网络中的在线卸载算法[11]–[20]。特别是,我们之前的工作[18]提出了一个混合框架,名为DROO(基于深度强化学习的在线卸载),以结合传统的基于模型的优化和无模型DRL方法的优势。DROO实现了一个DNN,根据输入环境参数(如信道条件)产生二进制卸载决策。候选卸载解决方案然后被馈送到基于模型的优化模块,该模块相应地优化通信/计算资源分配,并输出每个候选卸载决策的回报值的准确估计。集成的学习和优化方法导致在线训练过程更加健壮和更快的收敛,这得益于对应于每个采样动作的奖励值的精确估计。
除了优化计算性能,保证稳定的系统运行也同样重要,例如数据队列稳定性和平均功耗。然而,大多数现有的基于DRL的方法并没有强加长期的性能约束(例如[11]–[20])。相反,他们采用启发式方法,通过引入与例如分组丢弃事件[14],[15]和能量消耗[12],[20]相关的惩罚项来阻止每个时间帧中的不利动作。在线联合效用最大化和稳定性控制的一个著名框架是李雅普诺夫优化[21]。它将多阶段随机优化解耦为顺序的每阶段确定性子问题,同时为系统的长期稳定性提供理论保证。最近的一些工作已经应用李雅普诺夫优化来设计MEC网络中的计算卸载策略(例如[22]–[26])。然而,它仍然需要解决每个阶段子问题中的硬MINLP问题,以获得联合二进制卸载和资源分配决策。为了解决这一难题,一些著作设计了降低复杂性的启发式方法,如[25]中的连续松弛法和[26]中的解耦启发式方法。然而,这遭受了类似于[5],[6],[8],[9]中的性能-复杂性权衡困境。
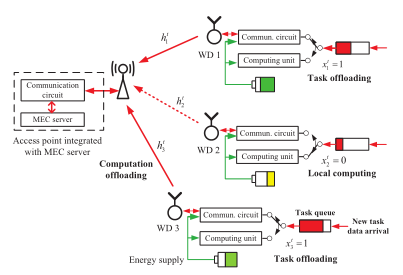
在本文中,我们考虑图1中的多用户MEC网络,其中计算任务数据在连续的时间帧中随机到达WDs的数据队列。我们的目标是设计一个在线计算卸载算法,在这个意义上,每个时间帧的决策是在不知道随机的未来实现的假设下做出的信道条件和数据到达。目标是根据长期数据队列稳定性和平均功率约束,最大化网络数据处理能力。为了解决这个问题,我们提出了一个基于李雅普诺夫指导的深度强化学习的在线卸载框架,该框架结合了李雅普诺夫优化和DRL的优点。在快变信道衰落和动态任务到达的情况下,LyDROO可以实时在线做出最优决策,同时保证系统的长期稳定性。据作者所知,这是第一个将李雅普诺夫优化和DRL相结合用于MEC网络在线计算卸载设计的工作。论文的主要贡献有:
1在线稳定计算卸载设计:考虑随机衰落信道和数据到达,我们将问题公式化为多阶段随机MINLP问题,以最大化所有WDs的长期平均加权和计算速率(即每秒处理的比特数),服从队列稳定性和平均功率约束。特别地,我们将在每个时间帧中做出最优卸载和资源分配决策,而不需要假设知道随机信道条件和数据到达的未来实现。
2集成李雅普诺夫-DRL框架:为了解决这个问题,我们提出了一个新的李雅普诺夫框架,它结合了李雅普诺夫优化和DRL的优点。特别地,我们首先应用李雅普诺夫优化将多阶段随机MINLP解耦为每帧确定性MINLP问题。然后在每一帧中,我们集成了基于模型的优化和无模型DRL,以非常低的计算复杂度来解决每帧的MINLP问题。特别地,我们表明所提出的LyDROO框架不仅保证了长期队列稳定性和平均功率约束,而且以在线方式获得了最优的计算速率性能。
3集成优化和学习:LyDROO采用演员-评论家结构来解决每帧MINLP问题。actor模块是一个DNN模块,它根据包括信道增益和对所有WDs的积压进行排队。批评模块通过解析地解决最优资源分配问题来评估二进制卸载动作。与在评论模块中使用无模型DNN的传统演员-评论结构相比,所提出的方法利用模型信息来获得对动作的准确评估,从而享有DRL训练过程的更健壮和更快的收敛。
4平衡探索和开发:LyDROO部署了一种有噪声的保序量化方法来生成卸载动作,该方法在DRL算法设计中优雅地平衡了探索和开发的权衡(即面向性能或多样性),以确保快速训练收敛。此外,该量化方法可以在训练过程中自适应地调整其参数,从而在不影响收敛性能的情况下显著降低计算复杂度。
仿真结果表明,该算法在满足所有长期稳定性约束的情况下,快速收敛到最优计算速率。与贪婪地最大化每个时间帧中的计算速率的短视基准算法相比,所提出的LyDROO实现了大得多的稳定容量区域,该区域可以在更重的任务数据到达和更严格的功率约束下稳定数据队列。
以往工作:
二进制和部分计算卸载是边缘计算系统中两种常见的卸载模型。前者要求计算任务的整个数据集作为一个整体在无线设备(WD)本地或在边缘服务器远程处理,而后者则允许数据集在WD和边缘服务器上并行分区和执行[2]。本文主要研究在线二进制卸载策略的设计,该策略广泛应用于物联网网络中,用于在不可分割的数据集上执行简单的计算任务。同时,我们在第七节中讨论了当计算任务由多个独立的子任务组成时,所提出的LyDROO方案在设计在线部分卸载策略中的应用。
为了解决采用二进制卸载模型的多用户MEC网络中难以解决的组合计算卸载问题,在文献中已经广泛探索了降低复杂度的算法。例如,[7]考虑WDs将其任务卸载给随机到达和离开的相邻节点。它提出了一个在线停止问题,并提出了一个低复杂度算法,其中每个WD以在线方式单独选择最佳的相邻节点集,以最小化最坏情况下的计算延迟。然而,所提出的方法不适用于优化本文所考虑的长期平均目标。[8]提出了一种坐标下降法,通过一次翻转一个用户的二进制卸载决策,迭代地找到局部最优。[5]应用吉布斯抽样以随机方式搜索决策空间。为了减少搜索维度,[8]提出了ADMM(交替基于乘子方向法)的方法,将原始组合优化分解为并行的一维子问题。除了基于搜索的元启发式算法,现有的工作还应用凸松弛来处理二元变量,如线性松弛[8],[25]和二次近似[9]。然而,上述优化方法在处理整数变量时不可避免地会遇到性能-复杂性权衡的困境,并且不适合在快速变化的环境下要求一致的高解决方案质量的在线实现。
DRL最近似乎是解决MEC网络在线计算卸载问题的一个有希望的替代方案。现有的基于DRL的方法采用基于值或基于策略的方法来学习从“状态”(例如,时变系统参数)到“动作”(例如,卸载决策和资源分配)的最佳映射。常用的基于价值的DRL方法包括深度Q学习网络(DQN)[11]–[13]、双DQN [14]和决斗DQN [15],其中DNN被训练来估计状态-动作价值函数。然而,当可能的离散卸载动作的数量很大时,基于DQN的方法是昂贵的,例如,WDs的数量呈指数增长。为了解决这个问题,最近的工作已经应用了基于策略的方法,例如行动者-批评家DRL[16]–[18]和深度确定性策略梯度(DDPG)方法[19],[20],以使用DNN直接构建从输入状态到输出动作的最优映射策略。例如,[19]考虑一个只采取离散卸载动作的WD,包括整数卸载决策和不可信的发射功率和卸载速率,并应用演员-评论家DRL方法来学习从连续输入状态到离散输出动作的最优映射。[18]和[20]训练两个独立的学习模块,以顺序生成离散的卸载决策和连续的资源分配。具体而言,[20]应用演员DNN来生成资源分配解决方案,由基于DQN的评论家网络连接来选择离散卸载动作。与[11]–[15]类似,当可能的卸载动作数量较大时,评估批评网络中的状态-动作值函数是困难的。另一方面,在[18]中提出的DROO框架使用一个参与者DNN来生成少量的二进制卸载决策,然后是一个基于模型的批评模块,该模块通过分析解决最优资源分配问题来选择最佳动作。得益于评论家模块获得的对动作的准确评估,即使演员DNN提供了非常少的动作(例如,在足够的迭代之后的两个动作)供评论家选择,DROO也能快速收敛到最优解。在本文中,我们将DROO嵌入到LyDROO框架中来解决每帧MINLP问题。
上述基于DRL的方法无法解决随机环境下的长期性能要求,例如队列稳定性和平均功率。在这方面,最近的研究应用李雅普诺夫优化设计了一种具有长期性能保证的在线卸载策略[22]–[26]。李雅普诺夫优化将多阶段随机问题解耦为每帧确定性子问题。对于每帧子问题,同样,[23]在每个时间范围内,仅安排一个用户卸载到多个ESs中的一个。在这两种情况下,二进制卸载变量的数量非常少,因此可以通过强力搜索获得最优解。[24]–[26]考虑多个用户的联合卸载决策。与本文考虑的二进制卸载策略不同,[24]允许WDs在本地和ES并行处理任务数据,并应用凸优化来解决连续联合卸载和资源分配问题。相比之下,[25]和[26]采用二进制卸载策略,其中可能的卸载解决方案的数量随着用户数量呈指数级增长。为了解决组合问题,[25]将二元变量放宽为连续变量。[26]提出了一种两阶段启发式算法,首先确定资源分配,然后利用匹配理论获得二进制卸载决策。然而,这些启发式方法不能保证始终如一的高解决方案质量,这最终可能会降低长期性能。
在图2中,我们说明了论文其余部分的组织。在第二节中,我们将稳定计算卸载问题表述为多阶段随机MINLP问题(P1)。在第三节中,我们应用李雅普诺夫优化将(P1)解耦成每帧确定性MINLP子问题(P2)。在第四节中,我们介绍了使用演员兼评论家DRL求解(P2)的莱德罗算法。参与者模块实现了一个DNN来解决二进制卸载子问题(P3),而批评者模块应用了一个定制的优化算法来解决连续资源分配问题(P4)。在第五节中,我们分析了LyDROO算法的性能。在第六节中,我们通过大量的仿真来评估所提出的算法。最后,我们在第七部分对论文进行了总结。
系统模型和问题表达
系统模型
如图1所示,我们考虑一个ES基站,它在等持续时间t的连续时间帧中辅助N个WD的计算。在第tth个时间帧内,我们将At i(以比特为单位)表示为到达第I个WD的数据队列的原始任务数据。我们假设到达时间服从一个二阶矩有界的一般分布,即,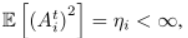
1,· · · , N.我们假设η的值是已知的,例如,通过根据过去的观察进行估计。在块衰落假设下,ht在一个时间帧内保持恒定,但在不同的帧内独立变化。
在tth时间帧中,假设标记的WD i处理Dt ibits数据,并在时间帧结束时产生计算输出。特别地,我们假设WDs采用二进制计算卸载规则[2]。也就是说,在每个时间范围内,原始数据必须在本地WD或远程ES进行处理。例如,在图1中,WD 1和wd3卸载它们的任务,而WD 2本地计算。卸载WDs共享公共带宽W,用于以时分多址方式将任务数据传输到ES。我们使用二进制变量xt ito表示卸载决策,其中xt i= 1和0分别表示WD i执行计算卸载和本地计算。
当WD本地处理数据(xt i= 0)时,我们将本地CPU频率表示为ft i,以fmax i为上限。本地处理的原始数据(以位为单位)和时间范围内消耗的能量为[2]
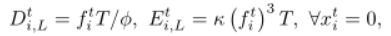
分别是。这里,参数φ > 0表示处理一位原始数据所需的计算周期数,而κ > 0表示计算能量效率参数。
否则,当数据卸载用于边缘执行时
我们将Pt表示为由最大功率Pt i≤ Pmax i和τt iT约束的发射功率,表示为分配给ith WD进行计算卸载的时间量。这里,τt I∏[0,1]和N i=1τt i≤ 1。数据卸载消耗的能量为Et i,O= Pt iτt iT。与[4]和[8]类似,我们忽略了边缘计算和结果下载的延迟,因此在时间范围内边缘处理的数据量为
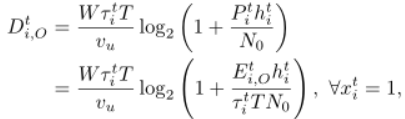
其中vu≥ 1表示通信开销,N0表示噪声功率。
让Dt i,(1 XT I)Dt I,L+xt iDt i,Oand Et i,(1 XT I)Et I,L+ xt iEt i,Odenote计算的位和时间帧t中消耗的能量。
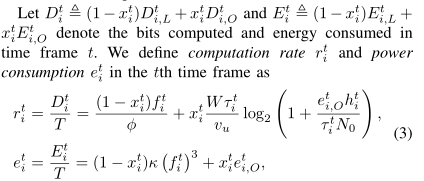
其中et i,O,Et i,O/T。为了说明简单,我们假设T = 1,在下面的推导中不失一般性。
让Qi(t)表示在第四个时间帧开始时第四个WD的队列长度。然后,队列动态可以建模为
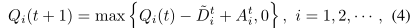
其中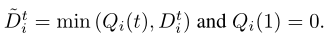
考虑无限排队容量的分析处理能力。在下面的推导中,我们实施了数据因果约束Dt i≤ Qi(t),这意味着Qi(t) ≥ 0适用于任何t。因此,队列动态被简化为
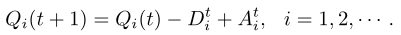
定义1
如果时间平均队列长度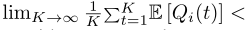 无穷,离散时间队列Qi(t)是强烈稳定的
无穷,离散时间队列Qi(t)是强烈稳定的
其中期望值是相对于系统随机事件而言的,信道衰落和任务数据到达。
Problem F ormulation
本文旨在设计一种在线算法,在数据队列稳定性和平均功率约束下,最大化所有WDs的长期平均加权和计算速率。特别地,我们在每个时间帧中进行在线决策,我们优化特定时间帧的任务卸载和资源分配决策,而无需假设知道随机信道条件和数据到达的未来实现。
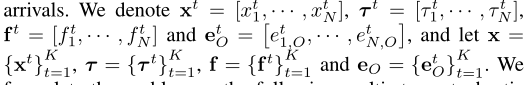
我们将该问题表述为以下多阶段随机MINLP问题(P1):
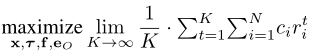
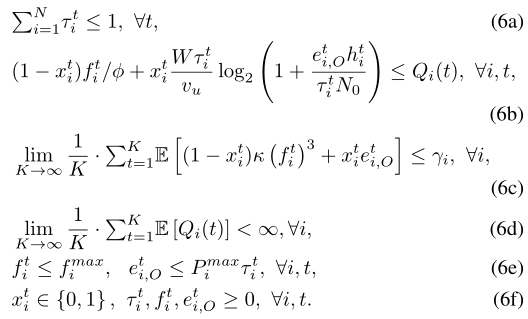
这里,cide注意到了ith WD的固定重量。(6a)表示卸载时间限制。请注意,如果xt i= 0,τt i= et i,O= 0必须保持在最佳值。同样,如果xt i= 1,ft i= 0必须成立。(6b)对应于数据因果关系约束。(6c)对应于平均功率约束,γ是功率阈值。(6d)是数据队列稳定性约束。在随机信道和数据到达的情况下,在不知道随机信道条件和数据到达的未来实现的情况下,当在每个时间帧中做出决策时,很难满足长期约束。此外,快速变化的信道条件要求在每个短时间帧内进行实时决策,
在下文中,我们提出了一个新颖的LyDROO框架,它以高鲁棒性和高效率解决了(P1)问题。

备注1:在结束本次会议之前,我们对建议的LyDROO算法的可能扩展进行评论。(P1)在目标中使用线性效用函数。然而,我们将在第四节后面说明,只要资源分配问题(P4)能够得到有效解决,拟议的LyDROO框架适用于解决广泛的问题。例如,我们可以考虑一个一般的非递减凹函数U (rt i),使得相应的(P4)是一个凸问题,例如,α ≥ 0且α 6= 1的α-公平函数(1α)1(rt I)1α,比例公平函数ln(rt i),或其他合适的QoS(服务质量)实用程序(见[27]和其中的参考文献)。为了分析清楚,我们在本文中考虑一个特定的线性效用函数来突出LyDROO框架的特征。
基于李雅普诺夫的多级MINLP解耦
在本节中,我们应用李雅普诺夫优化将P1解耦到每帧确定性问题中。为了应对平均功率约束(6c),我们引入了N个虚拟能量队列{Yi(t)}N i=1,每个WD一个。具体来说,我们将Yi(1) = 0,并将队列更新为
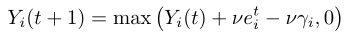
对于i = 1,N和t = 1,K,其中et iin (3)是第tth个时间帧的能耗,ν是正比例因子。Yi(t)可以看作是一个具有随机“能量到达”νet和固定“服务速率”νγi的队列,直观地说,当虚拟能量队列稳定时,平均功耗et i(即虚拟队列到达速率)不超过γi,从而满足(6c)中的约束。
为了共同控制数据和能量队列,我们定义Z(t) = {Q(t),Y(t)}为总队列积压,其中Q(t)= { Qi(t)} N I = 1,Y(t) = {Yi(t)}N i=1。然后,我们引入李雅普诺夫函数L(Z(t))和李雅普诺夫漂移∏L(Z(t))作为[21]
为了在稳定队列Z(t)的同时最大化时间平均计算速率,我们使用了漂移加惩罚最小化方法[28]。具体来说,我们寻求在每个时间帧t最小化以下漂移加惩罚表达式的上限:
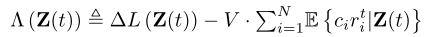
其中V > 0是衡量处罚的“重要性”权重。下面,我们导出λ(Z(t))的一个上界。首先,我们有
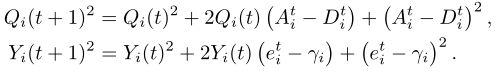
通过计算两边N个队列的总和,我们得到
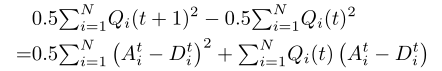
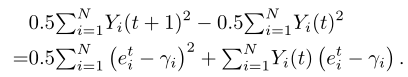
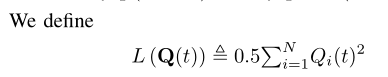
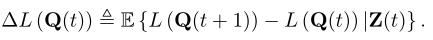
这里,b1i是一个常数,通过下式获得
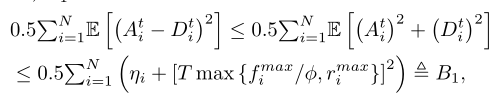
第二个不等式成立,因为
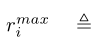
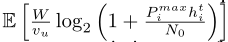 对应于第i波的最大平均传输速率。
对应于第i波的最大平均传输速率。
同样,我们定义
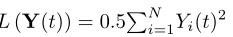
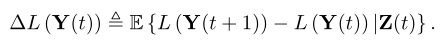
我们通过取两边的期望得到以下结果
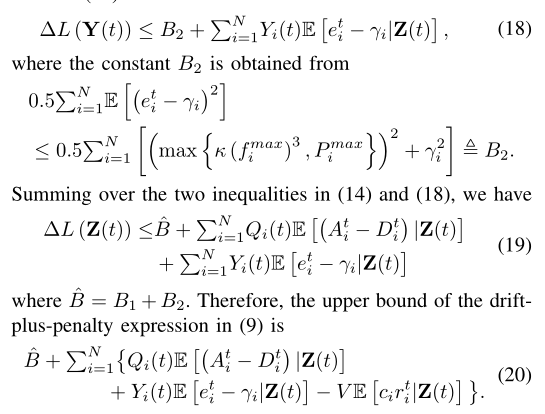
在tth时间框架内,我们应用机会期望最小化技术[21]。也就是说,我们观察队列积压Z(t),并相应地决定联合卸载和资源分配控制动作,以最小化(20)中的上限。请注意,只有第二项与tth时间范围内的控制动作相关。通过在tth时间帧开始时从观测值中去除常数项,该算法通过最大化来决定动作
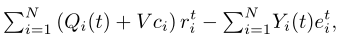
其中t和I在(3)中。直观地说,它倾向于增加具有长数据队列积压或大权重的WDs的计算速率,同时惩罚那些已经超过平均功率阈值的WDs。我们为每个WD i引入一个辅助变量rt i,Ofor,并表示rt O=?不是吗?N i=1。考虑到每帧约束,我们在tth时间帧内解决了以下确定性每帧子问题(P2)
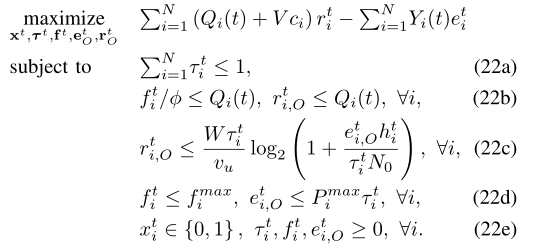
注意,上面的约束(22b)和(22c)等价于(P1)中的(6b),因为在最佳情况下(6b)的左侧正好有一个非零项。在第五节中,我们将展示我们可以通过在线解决每帧子问题来满足(P1)的所有长期约束。然后,剩下的困难在于在每个时间框架内解决MINLP (P2)。在接下来的部分,我们提出了一个基于DRL的算法来有效地解决(P2)。
在线计算卸载的李雅普诺夫引导DRL方法
回想一下,为了在第四个时间框架内解决(P2),我们观察到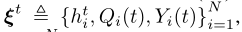
包括信道增益{ ht i } N i =和系统队列状态{Qi(t),Yi(t)}N i=1,并相应地决定控制动作{xt,yt},包括二进制卸载决策xt和连续资源分配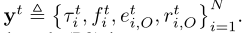 仔细观察表明,虽然(P2)是一个非凸优化问题,但如果xtis固定,优化ytis的资源分配问题实际上是一个”容易”的凸问题。在第四节中。我们将提出一个定制的算法来有效地获得给定xtin (P2)的最优yt。这里,我们表示G?xt,ξt?通过优化给定的卸载决策xt和参数ξt,作为(P2)的最优值。因此,求解(P2)等价于找到最优卸载决策(XT)∞,其中
仔细观察表明,虽然(P2)是一个非凸优化问题,但如果xtis固定,优化ytis的资源分配问题实际上是一个”容易”的凸问题。在第四节中。我们将提出一个定制的算法来有效地获得给定xtin (P2)的最优yt。这里,我们表示G?xt,ξt?通过优化给定的卸载决策xt和参数ξt,作为(P2)的最优值。因此,求解(P2)等价于找到最优卸载决策(XT)∞,其中
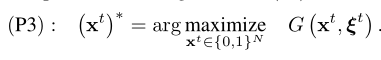
一般来说,获得(XT)⊙需要枚举2个负载决策,即使当N适中(例如,N = 10)时,这也会导致显著高的计算复杂度。当N较大时,其他基于搜索的方法,如分枝定界和块坐标下降[29],也很耗时。在实践中,这两种方法都不适用于快速变化信道条件下的在线决策。利用DRL技术,我们提出了一个LyDROO算法来构造一个策略π,它从输入ξ映射到最优动作(XT)∞,即π:ξT7 →( XT)∞,具有非常低的复杂度,例如,当N = 10时,几十毫秒的计算时间(即从观察ξtto到产生控制动作{xt,yt}的持续时间)。
Algorithm Description
如图3所示,LyDROO由四个主要模块组成:接受输入ξ并输出一组候选卸载动作{xt i}的actor模块,评估{xt i}并选择最佳卸载动作xt的评论家模块,策略更新模块随时间改进actor模块的策略,以及排队模块在执行卸载动作后更新系统队列状态{Qi(t),Yi(t)} N I = 1。通过与随机环境{ht i,At i}N i=1的重复交互,四个模块以顺序和迭代的方式运行,如下所述。
1)参与者模块:
演员模块由DNN和动作量化器组成。在tth时间帧的开始,我们将DNN参数表示为θt,当t = 1时,该参数按照标准正态分布随机初始化。
将观测值ζ作为输入,DNN输出一个宽松的卸载决策,稍后将被量化为可行的二进制动作,投入产出关系表示为: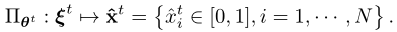
众所周知的通用近似定理声称,如果在神经元上应用适当的激活函数,例如sigmoid、ReLu和tanh函数,具有足够数量神经元的多层感知器可以精确地近似任何连续映射[30]。这里,我们在输出层使用sigmoid激活函数。
然后,我们将连续的XT量化为Mt可行的候选二进制卸载动作,其中MtI是一个依赖于时间的设计参数。量化函数表示为: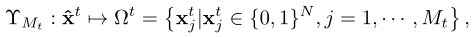 其中ωt表示tth时间帧中的一组候选卸载动作。υ表示量化函数,生成Mt = |ωt |二进制操作的。一个好的量化函数应该在生成卸载动作时平衡勘探-开发权衡,以确保良好的训练收敛。
其中ωt表示tth时间帧中的一组候选卸载动作。υ表示量化函数,生成Mt = |ωt |二进制操作的。一个好的量化函数应该在生成卸载动作时平衡勘探-开发权衡,以确保良好的训练收敛。
直观上,xtj应该接近xt(通过欧几里德距离测量),以有效利用DNN的输出,同时充分分离,以避免在训练过程中过早收敛到次优解。在这里,我们应用了噪声保序(NOP)量化方法[31],它可以生成任何Mt≤ 2N的候选动作。NOP方法通过应用[18]至[18]中的保序量化器(OPQ)来产生第一个Mt/2动作(Mt假设为偶数)。具体而言,第一个动作xt 1= [xt 1,1,,xt 1,N]计算如下
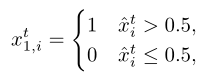
对于i = 1,N .为了生成下一个Mt/2-1动作,我们根据到0.5的距离对ˇXT的条目进行排序,使得|ˇXT(1)0.5 |≤|ˇXT(2)0.5 |≤|ˇXT(I)0.5 |≤|ˇXT(N)0.5 |,其中ˇXT(I)表示ˇXT的第一个有序条目。然后,将’ xt(I ‘ s ‘用作量化’ xt ‘的决策阈值,其中,对于m = 2,Mt/2,第m个动作xt m是从’ XT ‘和’ XT(m-1)的条目式比较中获得的。也就是说,
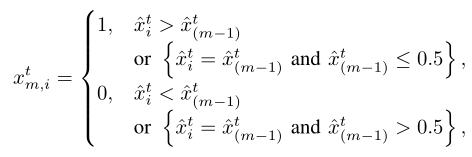
对于i = 1,,N .为了获得剩余的Mt/2动作,我们首先生成xt的噪声版本,表示为xt= Sigmoid(xt+ n),其中随机高斯噪声N∞N(0,in)与INbeing是一个单位矩阵,Sigmoid()是元素式Sigmoid函数,它限制XT IN(0,1)的每个条目。然后,我们通过对xt应用OPQ来产生剩余的Mt/2动作xt m,对于m = Mt/2 + 1,,Mt,即将xt替换为xtin (26)和(27)。
评论模块:
在演员模块之后,评论模块评估{xt i}并选择最佳卸载动作xt。与使用无模型的DNN作为评价网络来评价动作的传统行为者-评价者结构不同,LyDROO利用模型信息通过解析地解决最优资源分配问题来评价二进制卸载动作。这使得批评模块能够对卸载动作进行准确评估,从而实现DRL训练过程的更稳健和更快速的收敛。
具体来说,LyDROO选择最佳动作xtas
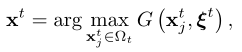
G在哪里?xt j,ξt?是通过优化给定xt jin (P2)的资源分配获得的。我们将介绍获得G的详细算法?xt j,ξt?在第四章b节中,请注意G的计算?xt j,ξt?是由Mttimes执行的,以获得最佳动作xt。直观地说,更大的Mt导致更好的解决方案性能,但计算时间更长。为了平衡性能和复杂度的权衡,我们在这里提出了一个自适应过程来设置时变Mt。
关键的想法是,当演员DNN随着时间的推移逐渐接近最优策略时,一个小团队会在到文本的一小段距离内找到最优动作。将Mt∈0,Mt 1]表示为最佳动作xt∈ωt的索引。我们定义m∫t = mod(Mt,Mt/2),它表示Mt/2无噪声或有噪声的候选动作中XT的顺序。在实践中,我们最初设置最大M1= 2N,并且每隔δM≥ 1个时间帧更新一次。如果在时间帧t中mod (t,δM) = 0,即t可以除以δM,我们设置 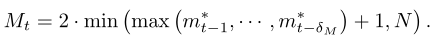
第一项中的附加1允许Mtto随时间增加。否则,Mt = Mt 1 if mod(t,δM) 6= 0。请注意,过于频繁的更新(较小的δM)可能会降低训练收敛性,而过大的δM会导致不必要的计算复杂性。
策略更新模块:
莱德罗用什么?不,不?作为更新DNN政策的标记输入输出样本。特别是,我们维护一个重放存储器,它只存储最近的q数据样本。实际上,在最初内存为空的情况下,我们在收集了q/2以上的数据样本后开始训练DNN。然后,每隔δTtime个时隙对DNN进行一次周期性训练,以避免模型过度拟合。当mod (t,δT) = 0时,我们随机选取一批数据样本{(οτ,xτ),τ ∈ St},其中St表示所选样本的时间索引集合。然后我们通过最小化平均交叉熵损失函数来更新DNN的参数?θt?使用Adam算法对数据样本进行分析
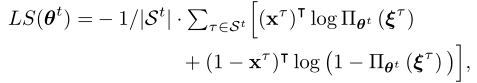
其中|St|表示样本批次的大小,()|表示转置运算符,log函数表示
向量的逐元素对数运算。训练完成后,我们在下一个时间帧中将actor模块的参数更新为θt+1。

排队模块:
作为批评模块的副产品,我们获得了与xt相关的最优资源分配。因此,系统执行联合计算卸载和资源分配动作{xt,yt},其处理数据{ Dt i } N i =并消耗能量{ et I } N I = 1,如(3)中给出的。基于{Dt i,At i } N i = 1和在第tth时间帧中观察到的数据到达{At i}N i=1,排队模块然后在第(t + 1)时间帧开始时使用(5)和(7)更新数据和能量队列{Qi(t + 1),Yi(t + 1)}N i=1。当无线信道增益观测值{ht+1 i }N i=1时,系统馈入输入参数ξt+1=?ht+1 i,Qi(t + 1),Yi(t + 1)?n I = 1到DNN,并从步骤1中的参与者模块开始新的迭代)。
通过上面的参与者-批评者-更新循环,DNN始终从最佳和最新的状态-动作对中学习,从而产生更好的策略πθt,该策略逐渐逼近要求解的最优映射(P3)。我们总结了算法1中LyDROO的伪代码,其中主要的计算复杂度在计算G的第7行?下一个,是吗?通过解决最优资源分配问题。这实际上表明,当考虑目标中的一般非减凹效用U (rt i)时,所提出的LyDROO算法可以扩展到求解(P1),因为计算G?下一个,是吗?是一个可以有效解决的凸问题,这里省略了详细的分析。在下一小节中,我们提出了一种低复杂度的算法来获得G?下一个,是吗?。
低复杂度最优资源分配算法
给定xtin (P2)的值,我们将xt i= 1的用户索引集表示为Mt 1,互补用户集表示为Mt 0。为了简单说明,我们去掉上标t,表示计算G?xt,ξt?如下
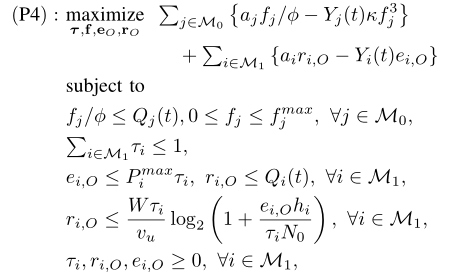
实验部分
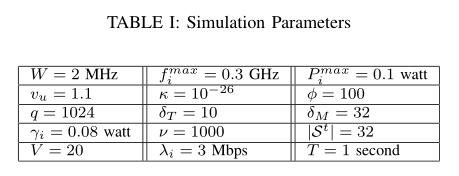
在这一部分,我们使用仿真来评估所提出的LyDROO算法的性能。所有计算都是在配备英特尔酷睿i5-4570 3.2GHz CPU和12 GB内存的TensorFlow 2.0平台上进行评估的。
我们假设平均信道增益遵循路径损耗模型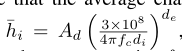 ,其中Ad= 3表示天线增益,fc= 915 MHz表示载波频率,de= 3表示路径损耗指数,米中的D1表示第一个WD和第二个es之间的距离。
,其中Ad= 3表示天线增益,fc= 915 MHz表示载波频率,de= 3表示路径损耗指数,米中的D1表示第一个WD和第二个es之间的距离。
提出的LyDROO在actor模块中采用全连接多层感知器,由一个输入层、两个隐藏层和一个输出层组成,其中第一和第二隐藏层分别有120和80个隐藏神经元。为了进行性能比较,我们考虑两种基准测试方法:
李亚普诺夫引导的坐标体面(LyCD):它最小化(20)中的漂移加惩罚的上限,或等效地求解(P2),使用坐标体面(CD)方法[8],迭代地应用一维搜索来更新二进制卸载决策向量xt。尽管(P2)的最优解很难获得,但我们通过大量的仿真验证了CD方法获得了接近最优的性能。因此,我们将LyCD视为LyDROO算法的目标性能基准。然而,LyCD的主要缺点在于当N较大时的显著计算延迟。我们在随后的模拟中表明,所提出的LyDROO实现了与LyCD相似的计算性能,但需要更短的计算时间。
提出的LyDROO在actor模块中采用全连接多层感知器,由一个输入层、两个隐藏层和一个输出层组成,其中第一和第二隐藏层分别有120和80个隐藏神经元。为了进行性能比较,我们考虑两种基准测试方法:
李雅普诺夫导向坐标下降(LyCD):
它最小化(20)中的漂移加惩罚的上限,或者等效地求解(P2),使用坐标体面(CD)方法[8],迭代地应用一维搜索来更新二进制卸载决策向量xt。尽管(P2)的最优解很难获得,但我们通过大量的仿真验证了CD方法获得了接近最优的性能。因此,我们将LyCD视为LyDROO算法的目标性能基准。然而,LyCD的主要缺点在于当N较大时的显著计算延迟。我们在随后的模拟中表明,所提出的LyDROO实现了与LyCD相似的计算性能,但需要更短的计算时间。
近视优化: